If you are on the look for an aesthetic worldwide topographic map (with contour lines, …) OpenTopoMap is worth a “visit” (https://opentopomap.org). With “XYZ-Connections” it is also a quite usefull basemap within QGIS projects.
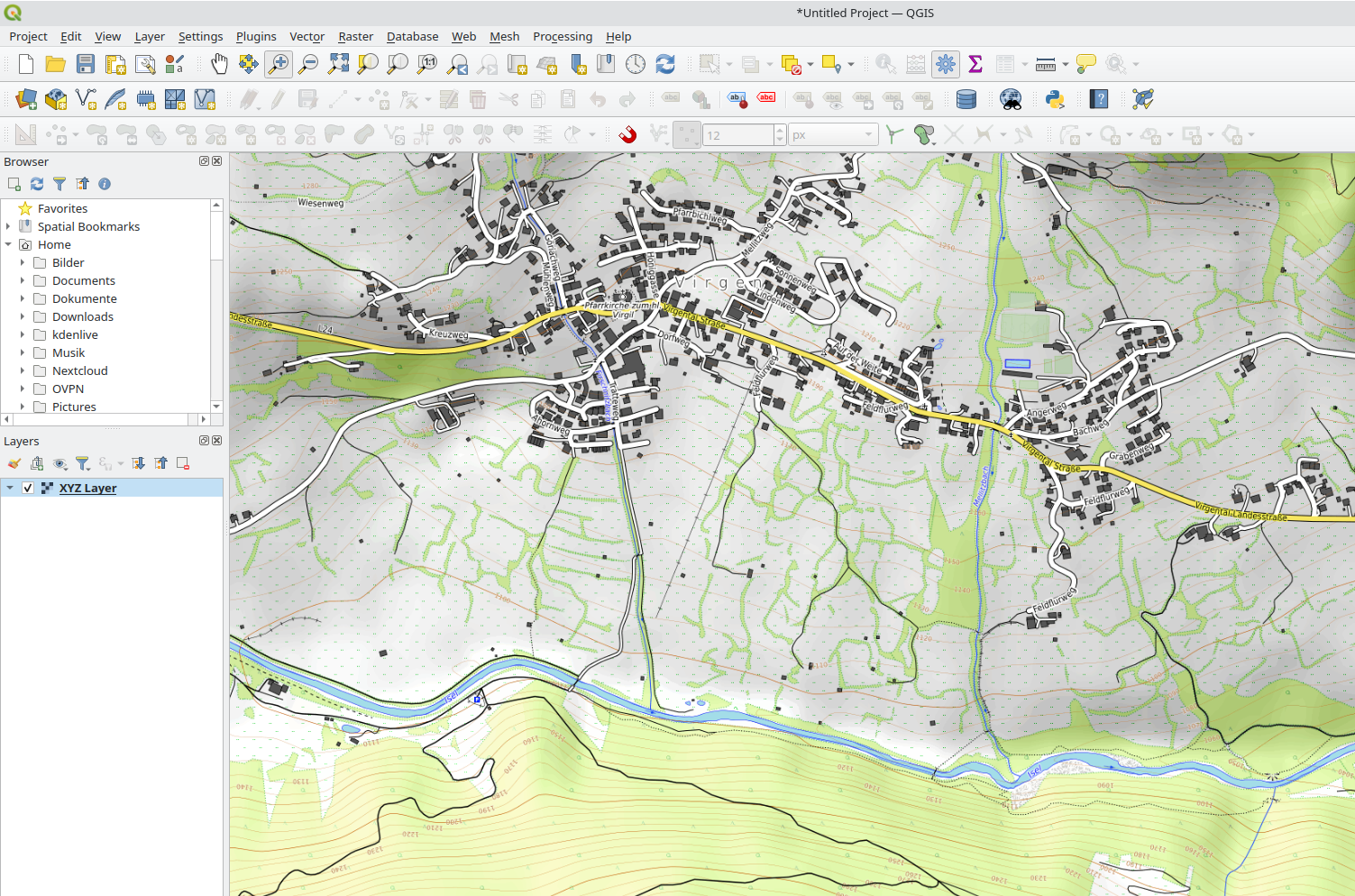
If you are on the look for an aesthetic worldwide topographic map (with contour lines, …) OpenTopoMap is worth a “visit” (https://opentopomap.org). With “XYZ-Connections” it is also a quite usefull basemap within QGIS projects.
Heureka, Fedora 38 Beta with Kernel 6.2.x supports RTL8852BE Wifi and Bluetooth out of the box 🙂 The manual work like described in Kubuntu 22.04 on Lenovo ThinkBook 14 G3 ACL is not necessry anymore.
Multiple tools exist for managing and reading scientific publications with open source and standards in mind; only Zotero, JabRef and others remain.
Manage and read everywhere related to PC/Tablet/Phone, but for an easy solution with Zotero, you need a paid subscription if you exceed 300MB of online storage, which I do.

Are you one of those who ended up with this nice banner every time you use a Microsoft Office product on an iOS/iPad device?

The Lenovo ThinkBook 14 G3 ACL is a well equipped device with a Ryzen 7 CPU and decent built-quality. The keyboard has a backlight feature, but not the quality and key drop a typical ThinkPad keyboard has – and the typical ThinkPad Trackpoint is missing 🙁 Installing Linux (Kubuntu 22.04, Kernel 5.15) works well if there would not be the Realtek RTL8852BE WiFi with integrated Bluetooth.
Kubuntu 22.04 on Lenovo ThinkBook 14 G3 ACL weiterlesenSome apartments and houses sometimes have a terrible placement of light switches. Therefore, drilling and placing new cables do not seem worth it. For example, a different solution is to set up a smart home system to control smart lights.

Thanks to the FOSS4G speech “FOSS4G – Cloud optimized formats for rasters and vectors explained,” I got first contact with the vector-format “FlatGeobuf” – and surprise also QGIS supports it 🙂 . That was an obvious starting point for testing it with some vector data and a poor network connection (~16 MBit).
FlatGeobuf – vector performance for the cloud (tested with QGIS 3.24) weiterlesen
Since the end of october 2021 the meteorological service of Austria (ZAMG) provides datasets for free on the “ZAMG Data Hub“.
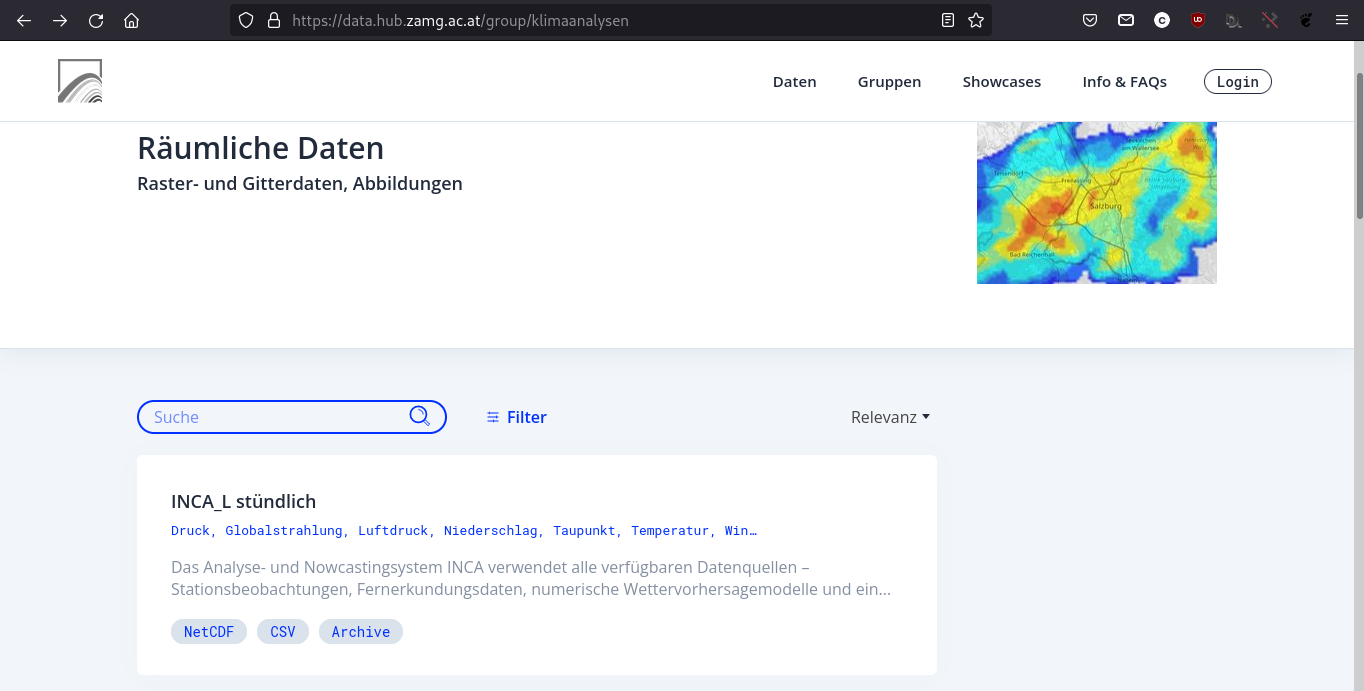
In addition to typical meteorological data from weather-stations, also a category with “spatial data” is available – so let’s have a look on the data with QGIS and the NetCDF datasets with timestamps.
Using Austrian weather&climate data with QGIS – ZAMG Data Hub weiterlesen
How to set up a simple static markdown-based blog for a personal journey diary and more?
Simple, use an offline CMS such as Hugo or Ghost and host it via GitLab or GitHub. Let’s see how to do that.
Altough the HP Elitebook 745 G2 (AMD Hardware) has some age, it’s a nice working-tool with good built-quality and mine works fine after 6 years intense use. BUT: HP reports the most recent BIOS versioned 1.48 – the BIOS internal update tool reports no update available based on V 1.44

HP Elitebook 745 G2 (AMD) – Reports no BIOS-Update to 1.48 available weiterlesen