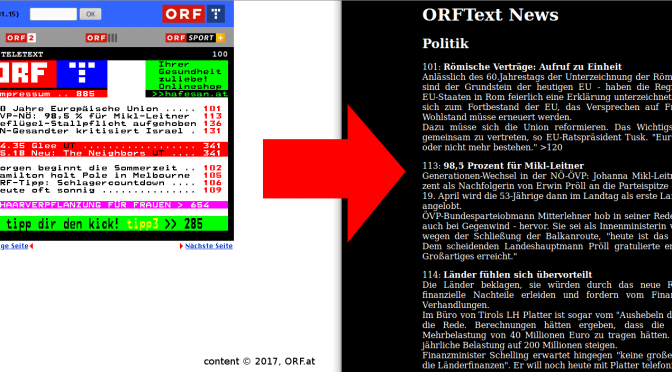
Believe it or not, tens millions of people are still reading Teletext. The biggest provider of on-screen news, the BBC, has shut down its CeeFax in 2012, but many stations all over Europe still broadcast a teletext signal1. There even is a (semi-) regular Art Festival about teletext!
For those not in the know: Teletext, invented by the BBC in 1972/1974, is a digital signal, that puts a 40×25, 8 color character grid onto your screen. Rudimentary (pseudo-)graphics in the form of a graphical character set are available too. The information is sorted into pages (often called tables), from 100 to 899, and subpages2.



Austrian Broadcasting Cooperation has been operating a Teletext service for ages too, and are putting dozens of pages of news reports on the air every day. Often, this information is not available anywhere else; a pity, as I think this is the twitter for editorial news.
I implemented a server software, that fetches Teletext from a DVB signal and processes it into either plain text or HTML, removing all the line breaks and hyphenation dictated by the small grid of the teletext service.
ttxd, as I called my creation, is comprised of multiple programs:
tzap, to tune the TV carddvbtext, to fetch teletext pagesvtx2ascii, to convert the binary VTX format to ascii (alt link)- some lines of
perl, to glue all of them together thttpd, as a simple web server
It took some digging to find both the dvbtext and vtx2ascii tools; Videotext seems to start to become a forgotten art. Back in the days of Video4Linux, the analogue TV ecosystem of drivers and tools, Teletext was a big part of it. Sadly, not many of these tools are still compatible with the newer digital DVB ecosystem.
Some of the tools I looked into to get teletext out of the transport stream were mtt and alevt and its sister-tools alevt-cap and alevtd. Those were however unsuitable for the following reasons: alevt, while nice to browse pages, can’t save them to disk or output them to stdout. mtt has a terminal / text only mode, but it uses ncurses for this and is therefore again unusable for my purpose.
alevt-cap seemed to be what I need – it is designed to fetch a number of pages and print them in plain text. But it blocks until all of the pages requested have been found. Since ORF text sometimes skips pages (i.e. not enough news to fill all the pages), the program would wait for those pages to come on the air forever and therefore never re-fetching other pages. A timeout seemed clunky, and doesn’t address the problem, that the amount of command line parameters (that hold a page to fetch each), is limited. A hack around that would be to start an instance of alevt-cap for each page I need, but that again isn’t a good solution.
alevtd, a little web server to convert teletext pages straight from the source to HTML, has not been updated to work with digital television, and patching seemed unreasonable.
Finally, I stumbled upon dvbtext, which fetches all pages from a teletext stream (identified by its PID) into a spool directory. It uses the .vtx format, which I believe to be more or less raw frames of videotext pages. And since not a whole lot can be found out, and reverse-engineering the ‘format’ was a task I didn’t want to spend my time on3, a pre made solution had to be found. vtx2ascii offered exactly what I needed. It was extremely hard to track down; the original web pages have disappeared, and aren’t available in the Internet Archive’s WayBack Machine. I got lucky, and found the code for it in an Emacs package, that uses it to display teletext inside that operating system Editor.
When the web server requests the Teletext listing, my Perl script will extract the plain text from those pages, remove the hypenation that has to be introduced to fit the messages into the tiny grid, slap a few HTML tags onto it and spit it back out to the server.
You can see the final result in the screen shot at the very top, or run your own instance, by cloning my repository!
1. technically, the teletext sent over DVB is quite different from analog PAL one, and is not a signal (neither was it on PAL, where it was transmitted between frames), but part of the MPEG transport stream). [1]
2Technically, there are even more: the first digit, the magazine is a three bit number, while the other two page digits, and the two subpage ones, are four bit; giving a total of [1-8][0-F][0-F].[0-F][0-F] = 52428810 = 8000016 possible subpages. Usually, about 1000-2000 pages are in use. Hexadecimal pages are often used for extra features, like TOPText or internal (non-published) pages.
3I do realize that that might be easier done than I imagined; clearing the most significant bit and removing control characters gives you a pretty usable output.